时间:2023-03-28 12:55:08来源:本站整理作者:点击:
最近在研究评分卡建模的流程,在特征处理的过程中涉及到分箱这一基本的常用技巧,本文就对分箱中的卡方分箱展开详细介绍。 分箱就是将连续型的数据离散化,比如年龄这个变量是,可以分箱为0-18,18-30,30-45,45-60。这也是建立评分卡过程中常见的操作,首先思考一个问题,为什么要进行分箱?直接用年龄这个变量去建模是否可以?其实是可以的。只不过评分卡需要模型有很强的业务可解释性,这和你的建模算法有关。如果你用xgb、lgb等机器学习算法的话,模型会变得不可解释,此时不分箱也是可以的。 分箱的好处主要有这些:
下面开始介绍卡方分箱,首先要先了解卡方检验。因为卡方分箱是一种基于卡方检验的分箱方法,具体来说是基于卡方检验中的独立性检验来实现分箱功能。
卡方检验就是对分类数据的频数进行分析的一种方法,它的应用主要表现在两个方面:拟合优度检验和独立性检验(列联分析)。
卡方检验也是一种假设检验,与常见的假设检验方法一致。
下面以年龄变量为例,讲解一下评分卡建模过程中如何对年龄变量进行卡方分箱。先举实际例子再讲理论。
首先,将年龄从小到大排序,每一个年龄取值为单独一箱。统计对应的违约和不违约的个数。然后进行合并,具体步骤如下:
分箱背后的理论依据:如果两个相邻的区间具有非常类似的类分布,那么这两个区间可以合并。否则,它们应该分开。低卡方值表明它们具有相似的类分布。
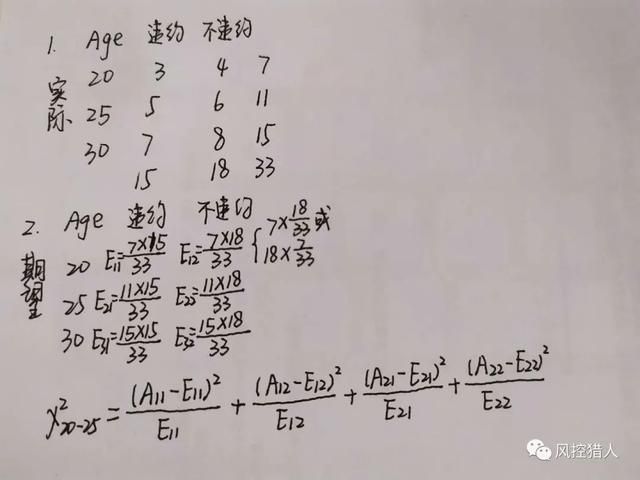
对于卡方值越小分布越相似这一核心理论我也做了个简单的推导:

可以看到如果需要合并的两箱分布完全一致的话,合并之后的卡方值为0。下面给出卡方分箱的理论及公式:
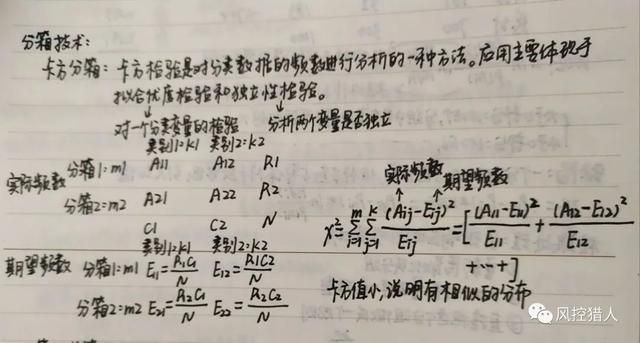
上面的步骤只是每一轮需要计算的内容,如果不设置停止条件,算法就会一直运行。当然,我们一般会设置一些停止条件:
根据经验值,卡方停止的阈值一般设置置信度为0.9、0.95、0.99,自由度可以设置为4是对应的卡方值,分箱数一般可以设置为5。卡方分箱的自由度是分类变量类型的个数减一。
下面给一个卡方分箱的代码,建议仔细阅读,有助于代码水平的提高和更好地理解卡方分箱。一定要一次性看完。
## 自写卡方最优分箱过程
def get_chi2(X, col):
'''
计算卡方统计量
'''
# 计算样本期望频率
pos_cnt = X['Defaulter'].sum()
all_cnt = X['Defaulter'].count()
expected_ratio = float(pos_cnt) / all_cnt
# 对变量按属性值从大到小排序
df = X[[col, 'Defaulter']]
df = df.dropna()
col_value = list(set(df[col]))
col_value.sort()
# 计算每一个区间的卡方统计量
chi_list = []
pos_list = []
expected_pos_list = []
for value in col_value:
df_pos_cnt = df.loc[df[col] == value, 'Defaulter'].sum()
df_all_cnt = df.loc[df[col] == value,'Defaulter'].count()
expected_pos_cnt = df_all_cnt * expected_ratio
chi_square = (df_pos_cnt - expected_pos_cnt)**2 / expected_pos_cnt
chi_list.append(chi_square)
pos_list.append(df_pos_cnt)
expected_pos_list.append(expected_pos_cnt)
# 导出结果到dataframe
chi_result = pd.DataFrame({col: col_value, 'chi_square':chi_list,
'pos_cnt':pos_list, 'expected_pos_cnt':expected_pos_list})
return chi_result
def chiMerge(chi_result, maxInterval=5):
'''
根据最大区间数限制法则,进行区间合并
'''
group_cnt = len(chi_result)
# 如果变量区间超过最大分箱限制,则根据合并原则进行合并,直至在maxInterval之内
while(group_cnt > maxInterval):
## 取出卡方值最小的区间
min_index = chi_result[chi_result['chi_square'] == chi_result['chi_square'].min()].index.tolist()[0]
# 如果分箱区间在最前,则向下合并
if min_index == 0:
chi_result = merge_chiSquare(chi_result, min_index 1, min_index)
# 如果分箱区间在最后,则向上合并
elif min_index == group_cnt-1:
chi_result = merge_chiSquare(chi_result, min_index-1, min_index)
# 如果分箱区间在中间,则判断两边的卡方值,选择最小卡方进行合并
else:
if chi_result.loc[min_index-1, 'chi_square'] > chi_result.loc[min_index 1, 'chi_square']:
chi_result = merge_chiSquare(chi_result, min_index, min_index 1)
else:
chi_result = merge_chiSquare(chi_result, min_index-1, min_index)
group_cnt = len(chi_result)
return chi_result
def cal_chisqure_threshold(dfree=4, cf=0.1):
'''
根据给定的自由度和显著性水平, 计算卡方阈值
'''
percents = [0.95, 0.90, 0.5, 0.1, 0.05, 0.025, 0.01, 0.005]
## 计算每个自由度,在每个显著性水平下的卡方阈值
df = pd.DataFrame(np.array([chi2.isf(percents, df=i) for i in range(1, 30)]))
df.columns = percents
df.index = df.index 1
pd.set_option('precision', 3)
return df.loc[dfree, cf]
def chiMerge_chisqure(chi_result, dfree=4, cf=0.1, maxInterval=5):
threshold = cal_chisqure_threshold(dfree, cf)
min_chiSquare = chi_result['chi_square'].min()
group_cnt = len(chi_result)
# 如果变量区间的最小卡方值小于阈值,则继续合并直到最小值大于等于阈值
while(min_chiSquare < threshold and group_cnt > maxInterval):
min_index = chi_result[chi_result['chi_square']==chi_result['chi_square'].min()].index.tolist()[0]
# 如果分箱区间在最前,则向下合并
if min_index == 0:
chi_result = merge_chiSquare(chi_result, min_index 1, min_index)
# 如果分箱区间在最后,则向上合并
elif min_index == group_cnt-1:
chi_result = merge_chiSquare(chi_result, min_index-1, min_index)
# 如果分箱区间在中间,则判断与其相邻的最小卡方的区间,然后进行合并
else:
if chi_result.loc[min_index-1, 'chi_square'] > chi_result.loc[min_index 1, 'chi_square']:
chi_result = merge_chiSquare(chi_result, min_index, min_index 1)
else:
chi_result = merge_chiSquare(chi_result, min_index-1, min_index)
min_chiSquare = chi_result['chi_square'].min()
group_cnt = len(chi_result)
return chi_result
def merge_chiSquare(chi_result, index, mergeIndex, a = 'expected_pos_cnt',
b = 'pos_cnt', c = 'chi_square'):
'''
按index进行合并,并计算合并后的卡方值
mergeindex 是合并后的序列值
'''
chi_result.loc[mergeIndex, a] = chi_result.loc[mergeIndex, a] chi_result.loc[index, a]
chi_result.loc[mergeIndex, b] = chi_result.loc[mergeIndex, b] chi_result.loc[index, b]
## 两个区间合并后,新的chi2值如何计算
chi_result.loc[mergeIndex, c] = (chi_result.loc[mergeIndex, b] - chi_result.loc[mergeIndex, a])**2 /chi_result.loc[mergeIndex, a]
chi_result = chi_result.drop([index])
## 重置index
chi_result = chi_result.reset_index(drop=True)
return chi_result
import copy
chi_train_X = copy.deepcopy(train_X)
## 对数据进行卡方分箱,按照自由度进行分箱
chi_result_all = dict()
for col in chi_train_X.columns:
print("start get " col " chi2 result")
chi2_result = get_chi2(train, col)
chi2_merge = chiMerge_chisqure(chi2_result, dfree=4, cf=0.05, maxInterval=5)
chi_result_all[col] = chi2_merge
>【作者】:Labryant
>【原创公众号】:风控猎人
>【简介】:某创业公司策略分析师,积极上进,努力提升。乾坤未定,你我都是黑马。
>【转载说明】:转载请说明出处,谢谢合作!~
, 伊利QQ星奶粉和小小CBA达成战略合作,2023年榛高篮球挑战赛全面开启
伊利QQ星奶粉和小小CBA达成战略合作,2023年榛高篮球挑战赛全面开启
父母家暴对孩子的影响,如何处理夫妻感情中的家庭暴力?父母家暴对孩子的影响,如何处理夫妻感情中的家庭暴力?
夫妻吵架总冷战怎么办?怎么和好并且化解夫妻吵架呢?林志玲登上11月杂志封面,做妈妈之后成为幸福的代名词“关公”陆树铭因病去世,网爆大衣哥亲往西安悼念,被赞有情有义《卿卿日常》24节气姑娘结局是什么_《卿卿日常》24节气姑娘离开老三了吗 关注公益慈善可以在哪里查询全国慈善组织的公开信息 蚂蚁庄园1月12日答案
关注公益慈善可以在哪里查询全国慈善组织的公开信息 蚂蚁庄园1月12日答案
Copyright 2022-2026 feiyundao.com 〖妃孕岛〗 版权所有 陕ICP备2022000637号-4
声明: 本站文章均来自互联网,不代表本站观点 如有异议 请与本站联系 本站为非赢利性网站 不接受任何赞助和广告